
От автора: вы когда-нибудь видели, чтобы веб-страница загружала встроенный объект, который действительно является тем же HTML, что и основной документ? Я видел это недавно на нескольких веб-сайтах, включая несколько крупных интернет-магазинов, новостных сайтов, сайте финансовых услуг и веб-сайте коммунальной компании. Каждый раз, когда я сталкивался с этим, я говорил, что мне нужно написать об этом в блоге. Итак, вот этот пост!
В двух последних случаях имела место та же ошибка. Можете ли вы определить, в чем она заключается?

Стиль body с свойством background, которое является сокращением для background-color, background-url и других. В этом примере разработчик, вероятно, хотел использовать пустой цвет фона background: none, но вместо этого использовал пустой URL-адрес url(). Функция пытается загрузить фоновое изображение, и оно принимает строку в качестве аргумента. Поскольку пустая строка является допустимой строкой, это не вызывает ошибки в консоли. Это просто приводит к относительному запросу к базовому URL.
Я создал простую тестовую страницу, чтобы продемонстрировать это. В водопаде WebPageTest ниже вы можете четко увидеть запрос дополнительной страницы.

В Chrome DevTools вы увидите, что дублирующийся запрос отображается с инициатором основного документа. В консоли нет индикации или ошибки. Возможно, это не техническая непреднамеренная ошибка, но она определенно приводит к снижению производительности.

В этой статье мы собираемся выяснить, почему это проблема производительности, как могут быть непреднамеренно инициированы повторяющиеся запросы HTML и как их избежать.
Каково влияние на производительность?
Для многих сайтов HTML-страницы генерируются динамически, а это означает, что доставка контента связана с внутренними затратами. Мы часто измеряем это с помощью метрики «Время до первого байта», которая сообщает нам время с момента отправки запроса до момента, когда браузер начинает получать ответ. Часто эти страницы также не кэшируются, поэтому каждый запрос обрабатывается динамически.
Общая емкость серверной части приложения обычно определяется его способностью обрабатывать получаемый объем рабочей нагрузки. А если вы случайно отправите вдвое больше запросов для динамически сгенерированной HTML-страницы, ваша инфраструктура может работать вдвое больше просто так. Например:
Если серверная часть изо всех сил пытается справиться с нагрузкой, это затронет все страницы. Это может снизить время до первого байта для всех страниц.
Масштабирование исходной емкости связано с затратами. В этом случае ненужные запросы HTML могут исказить планирование емкости.
Дополнительная причина — увеличенный размер страницы. Многие из приведенных ниже примеров использовались для создания заполнителей или пустого содержимого. В этих случаях дополнительный HTML может излишне увеличивать размер страницы.
Что вызывает это?
Вот несколько причин, из-за которых я видел повторяющиеся запросы HTML.
<body style="background: url('')">
Это пример, с которого я начал этот пост. Когда вы стилизуете элемент с использованием фонового URL-адреса url(), любая строка считается аргументом значения. Поскольку url(‘ ‘) передается допустимая строка, она переводится в относительный URL. Это вызывает повторяющийся запрос как в Chrome, так и в Firefox. Safari игнорирует пустую строку URL-адреса.
Это также относится к другим элементам, которые могут быть стилизованы с помощью фонового URL-адреса. Например, <div style=»background: url()»>. И это тоже случается с url(), url(»)и url(‘ ‘)!
Src элемента с ? или #
Для некоторых элементов атрибут src, имеющий значение «?» или «#» будет интерпретироваться, как пустой относительный URL. Например, <img src=»#» /> выглядит как пустое изображение-заполнитель, но при этом снова будет получен базовый HTML-код.
То же самое относится к тегам script, iframe и video — хотя в разных браузерах это немного различается. Например:
src=» » возвращает повторяющийся запрос для Firefox, но не для других браузеров.
<script src=»#» /> также дает эффект только на Firefox
<script src=»?» /> влияет только на браузеры Chrome
Chrome не отправляет повторяющиеся запросы на относительные атрибуты src видео, в отличие от Firefox и Safari.
В таблице ниже приведен полный обзор тестов, которые я провел в Chrome, Safari и Firefox, чтобы увидеть, как они обрабатывают эти ошибки. Значок предупреждения указывает, что они приводят к нескольким запросам HTML:

* iFrames с src=»?» и «#» привели к 3-4 запросам HTML для одной и той же страницы.
Кэширование Service worker
Создание отдельного слоя кеша с помощью Service worker — отличный способ предварительно загрузить кэш браузера для ресурсов, которые ему понадобятся позже. Однако что происходит, когда вы включаете HTML-страницу в качестве одного из ресурсов для извлечения?
Вот пример того, как сайт делает именно это. Хуже того, HTML не кешировался…
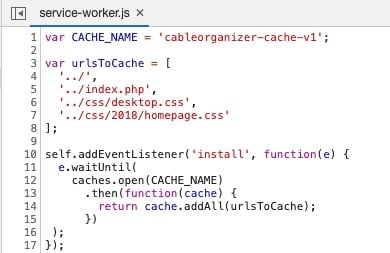
Если вы собираетесь использовать Service worker для кэширования ресурса, убедитесь, что этот ресурс кэшируется!
display: none
Хотя этот пример не относится конкретно к HTML, его стоит упомянуть. Как говорит @dougsillars, «display: none не означает download: none».

В этом примере разработчик ссылался на видеоконтент, который использовал медиа-запрос, чтобы скрыть видео для определенных размеров экрана. Конечным результатом было скачивание видео как для ПК, так и для мобильных устройств, при этом в одном случае оно было скрыто. Это много байтов, потраченных впустую!
Почему я упоминаю об этом в статье о повторяющихся запросах HTML? Я видел несколько случаев, когда этот метод использовался вместе с <img src=»#» />, что приводило к дублированию HTML!
Как обнаружить?
Я не знаю каких-либо инструментов, которые бы искали именно это, поскольку это, как правило, небольшая ошибка.
Вероятно, самый простой способ обнаружить это — взглянуть на графу обработки ЦП в WebPageTest. Если вы видите выполнение запроса JS до его загрузки, вероятно, это дубликат.

В DevTools вы также можете отфильтровать по своему доменному имени, используя domain:www.example.com. Фильтрация и сортировка по имени упрощает их. Если вы видите один и тот же URL-адрес с типом документа и текстом /html, значит, вы загружаете дублированную HTML-страницу.
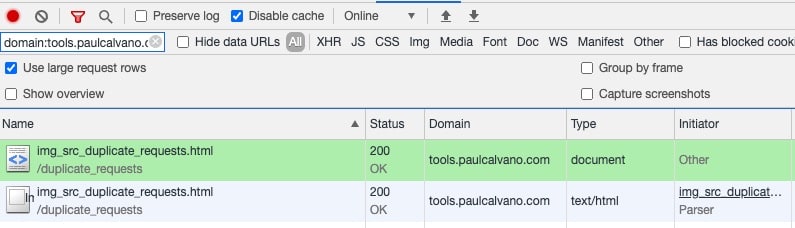
Клик по инициатору может помочь найти причину загрузки дублированного HTML.
Заключение
Если вы анализируете страницу и видите, что-то похожее на дублированный запрос базовой HTML-страницы, не игнорируйте это! Это может быть серьезной проблемой производительности. Вместо этого используйте DevTools, чтобы попытаться определить, что инициировало этот запрос. Вы можете обнаружить, что случайно включили заполнитель или установили неправильное свойство CSS или атрибут элемента src.
Автор: Paul Calvano
Источник: https://dev.to
Редакция: Команда webformyself.